AI代码能力的天花板,比你想象的低得多

ProgramBench 基准测试显示所有主流大模型在系统级代码生成任务上得分全部为 0%,这揭示了当前 AI 编程能力的真实边界。
2026-05-07
AI代码能力的天花板,比你想象的低得多
你可能听过各种AI编程有多厉害的叙事——Claude Code刷榜SWE-bench、GPT-5.5 Coding拿下93%准确率、Gemini 2.5 Ultra击败专业程序员……
但今天看到一组数据,让我愣了好几秒。
所有主流大模型,在ProgramBench上的得分,全部是 0%。
一个字面意义上的 "零"。
1. 0%是什么概念?
先科普一下。ProgramBench 是一个最近刚发布的代码生成基准测试,但它的测试方式跟以往那些妖艳贱货完全不一样。
传统的基准测试,像 HumanEval、SWE-bench 这些,考的是"局部手术"能力——给你一个有bug的函数,让AI修一下;给你一个算法题,让AI写个解法。这类任务,AI确实已经很能打了。
但 ProgramBench 上来就是一道大题:
无网络条件下,完整复现 ffmpeg、SQLite、ripgrep 这些复杂软件系统。
不是修一个函数,是从零开始,把一整个有几十万行代码、几十个模块、复杂依赖关系的系统给我重建出来。
考的不是"会不会写代码",考的是"能不能独立建模一个完整的软件系统"。
结果,所有模型,齐刷刷,0%。


2. 为什么传统基准一直在"注水"?
你可能会问:那之前的那些高分是怎么来的?
说实话,看到 ProgramBench 这个结果,我第一反应是去翻之前那些基准测试到底在测什么。
然后我意识到一个问题——我们一直在用"局部战斗"的数据,论证"全局作战"的能力。
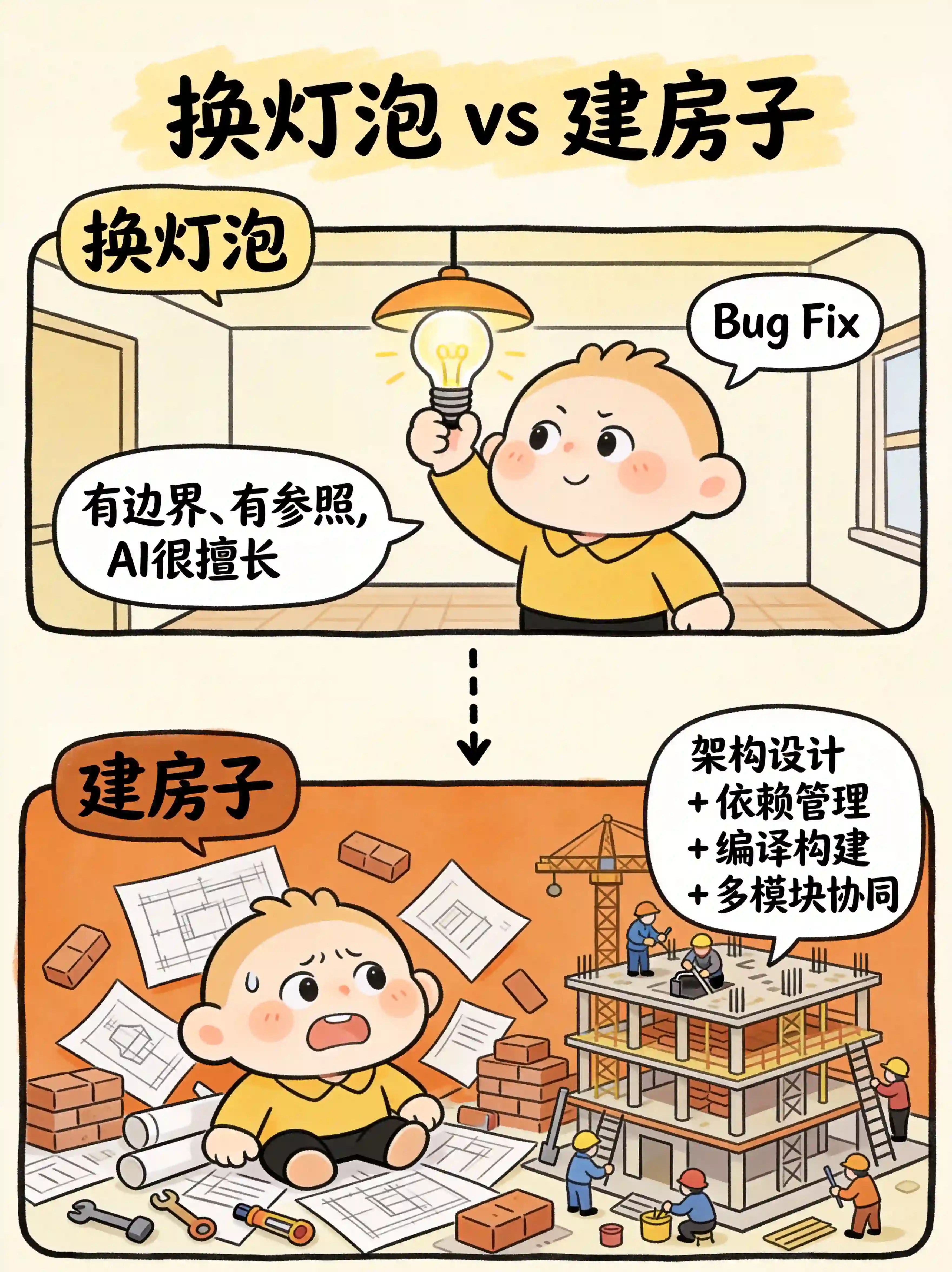
就像你不能因为一个人能精准地扣好一颗纽扣,就判断他能独立完成一套西装的定制。
HumanEval 考的是单函数实现,SWE-bench 考的是补丁级别的修复,这些任务有一个共同特点:有上下文、有边界、有参照。
你不是在造一座房子,你是在给一座已经建好的房子换个灯泡。
这当然有价值。但这不是"系统级软件工程能力"。
ProgramBench 第一次把测试拉到了这个维度——架构设计、依赖管理、编译构建、多模块协同。这才是真正考验AI"从零构建"能力的地方。
然后大家发现:离及格还差得远。
3. 0%背后的真实差距
说个我的理解,可能不太准确,但我觉得能说明问题。
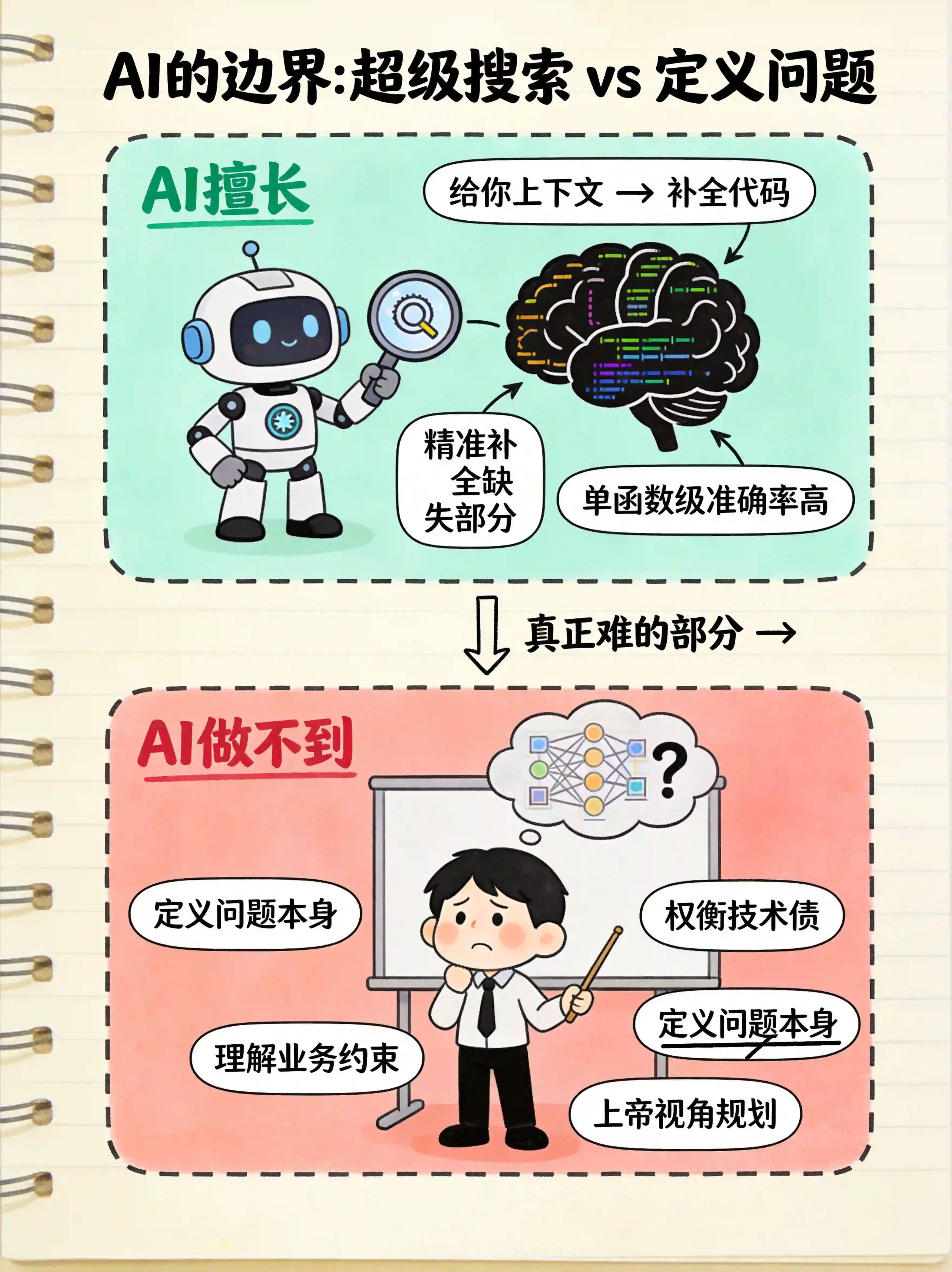
AI编程现在的能力,更像是一个超级搜索引擎 + 代码补全器。你给它一个清晰的上下文,它能帮你把缺失的部分补上,而且补得相当准确。
但软件工程真正难的部分是什么?
是定义问题本身。
一个生产级的系统,不是从"写代码"开始的,是从"理解要解决什么问题"开始的。要跟业务方反复对齐,要理解上下游的约束,要权衡技术债和迭代速度,要考虑可维护性……
这些东西,目前的AI基本上是无能为力的。不是技术问题,是信息不对称问题——AI没有上帝视角,它只能看到你喂给它的上下文。
所以回到 ProgramBench 的 0%——
它测的不是AI会不会写代码,是AI能不能在没有"参考答案"的情况下,独立完成一个复杂系统的架构和实现。
这件事,目前没有人做到。
4. 对企业级Agent开发意味着什么?
说这么多,你可能要问:这跟我做企业级Agent开发有什么关系?
关系大了。
我做了不少企业级项目,深刻体会到一件事——客户买的从来不是"能跑",是"能交代"。
什么意思?
你交付一个Agent给企业,人家要的不是你证明"AI能干活",人家要的是能写进汇报材料、能跟领导汇报、能通过审计的东西。
这背后需要的,是系统设计文档、架构图、接口规范、异常处理流程、监控告警配置……这些"工程化"的部分。
而这些东西,目前AI能帮你写的,都是模板化的。真要结合业务场景做定制,还是得人来。
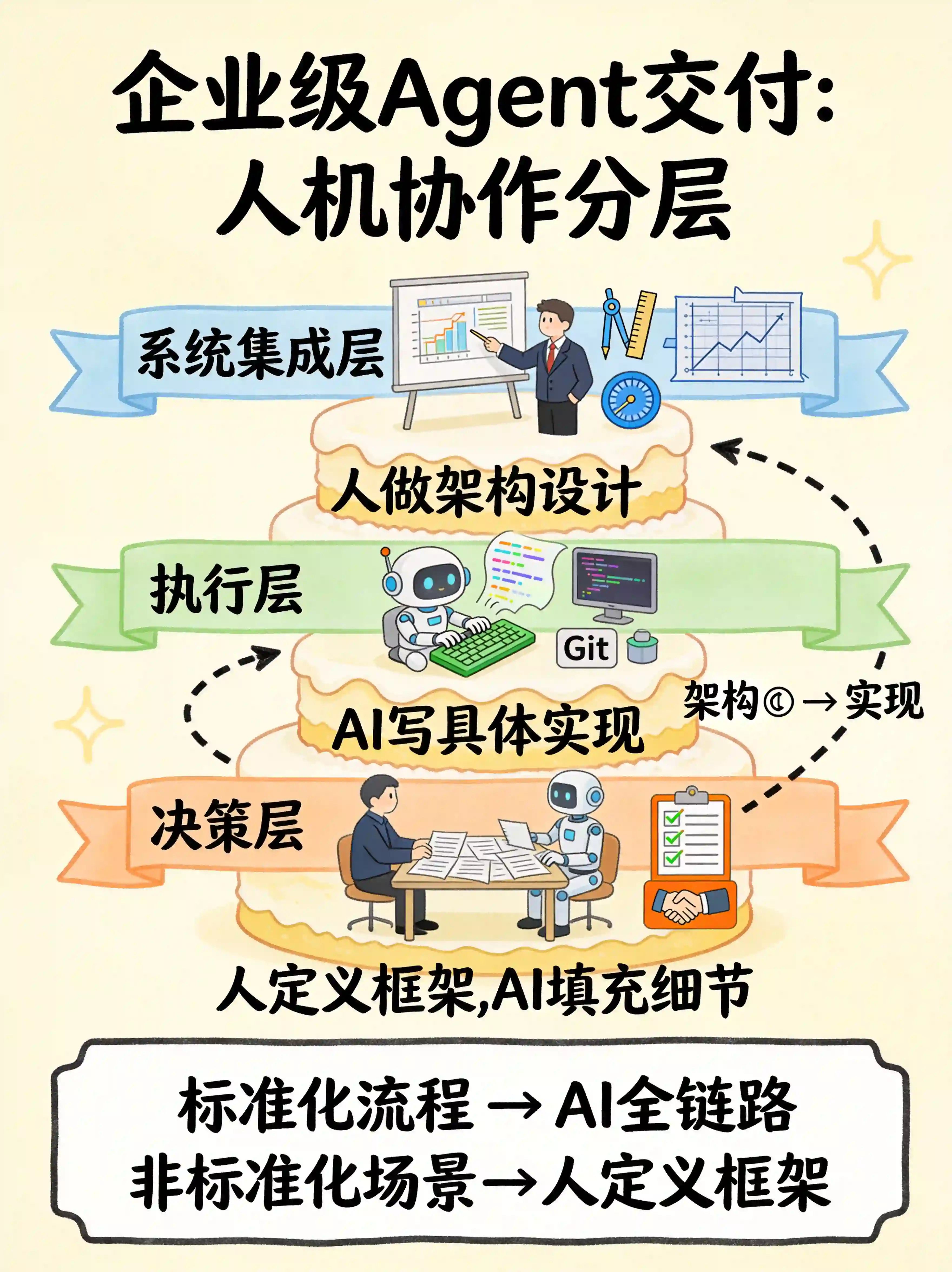
所以我现在的做法是:让AI做执行层的东西,把决策层留给人。
具体来说:
- 标准化流程:AI全链路搞定
- 非标准化场景:人定义框架,AI填充细节
- 系统集成:人来做架构设计,AI写具体实现
这样既享受了AI的效率,又保住了交付质量。
5. 写在最后
ProgramBench 的 0%,不是一个黑点,反而是一个清醒剂。
它告诉我们:AI编程被吹过头的那部分,是局部任务能力,不是系统级工程能力。
对于想靠AI编程创业、做产品的人来说,这反而是个好消息——因为门槛没有想象中那么低,你积累的系统设计能力、领域知识、业务理解,依然是有价值的护城河。
AI会替代的是"重复劳动",不是"复杂决策"。
搞清楚这个边界,比盲目追热点重要得多。
相关参考:ProgramBench 基准测试发布于 2026年5月7日